

본 포스팅에서는 실제 데이터를 바탕으로 음성 데이터 시각화와 음성 특징을 추출하는 방법을 알아보겠습니다.
데이터
활용하는 데이터는 AIHub에서 제공하는 '구음장애 음성인식 데이터'입니다(https://www.aihub.or.kr/). 본 데이터는 구음 장애 환자들의 한국어 음성 녹음 데이터와 관련된 여러 정보를 제공하고 있습니다. AIHub에서는 구음 장애 환자들의 음성을 바탕으로 언어 청각, 후두, 뇌기능의 질병으로 분류하는 샘플 모델을 제공하고 있습니다.
1. 메타 데이터 불러오기
먼저 데이터 시각화를 위해 '샘플 데이터'를 다운로드 받아 사용했습니다. 샘플 데이터 세트는 음성을 담고 있는 '원본 데이터'와 음성에 대한 여러 설명, 정보를 담고 있는 '라벨링 데이터'로 구성됩니다. 먼저 라벨링 데이터를 불러오고, 녹음된 음성의 대본인 "Transcript" 정보를 추출했습니다. 이후 데이터 프레임으로 저장합니다.
meta = pd.read_json('00_샘플_구음장애/라벨링데이터/TL01_뇌신경장애/25.언어+뇌신경장애/ID-02-25-N-KSM-02-03-M-45-JL.json', orient = 'columns')
pd.DataFrame(meta['Transcript'][0].split("."))
하나의 샘플 오디오가 총 53개의 문장으로 이루어진 것을 알 수 있습니다.

2. 음성 데이터 불러오기
이후 음성 데이터를 불러옵니다. 원본 음성 데이터는 약 30초 가량의 침묵 -> 한 마디 발화 -> 약 30초 가량의 침묵 -> 한 마디 발화 -> ... 이런 식으로 구성되어 있어서, 원본 음성을 발화/비발화 구간으로 나누었습니다. 관련 내용은 음성 데이터 전처리 포스팅에서 다루겠습니다. 아래 'processed_chucnk_9'는 약 5초 가량의 전처리된 한 마디 음성 데이터입니다.
음성 데이터 불러오기는 sampling rate (sr)에 따라 달라집니다. 예를 들어, 초당 16,000개(16,000Hz) 샘플을 가지고 있는 데이터는 1초에 음성 신호를 16,000번 샘플링합니다. 통상 사람의 목소리는 대부분 16,000Hz 안에 포함되기 때문에 sr을 16000으로 설정합니다. sr의 디폴트 값은 22,050Hz 입니다.
data, sample_rate = librosa.load('processed_chunk_9.wav', sr = 16000)
print('sample_rate:', sample_rate, ', audio shape:', data.shape)
print('length:', data.shape[0]/float(sample_rate), 'secs')
### result ###
sample_rate: 16000 , audio shape: (85529,)
length: 5.3455625 secs
음성 데이터 특징 추출
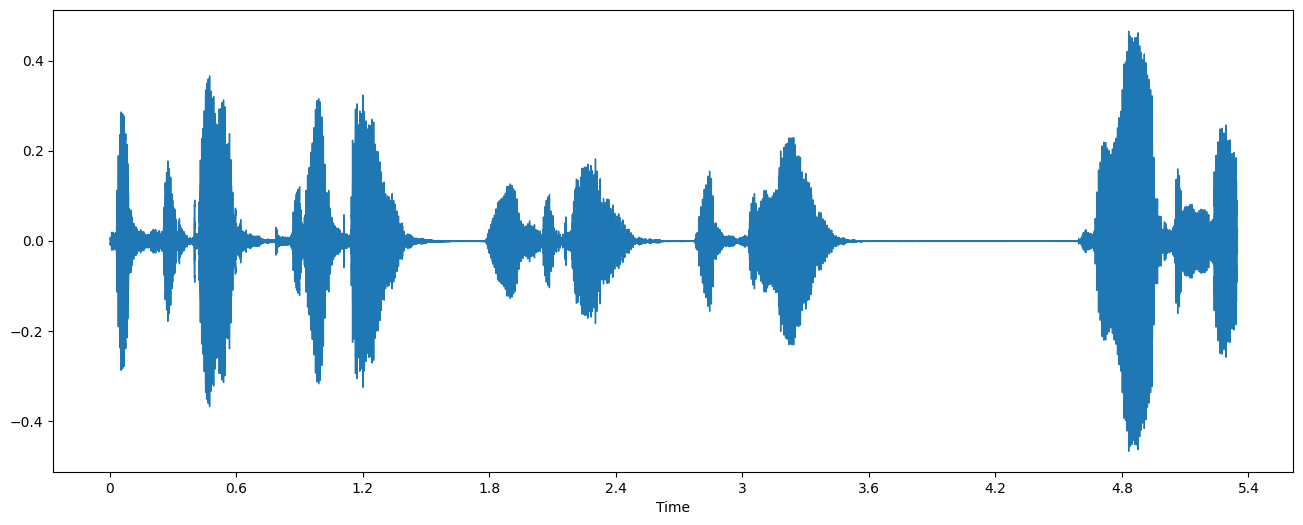
1. Waveform 시각화
Waveform은 음성 파일의 기본 형태입니다. 음성 데이터는 Waveform 데이터로 저장됩니다. 만약 16,000Hz로 녹음된 음성이라면 1/16,000 초 마다 들어온 소리가 어느정도 세기를 가지고 있는지 기록합니다. 음성은 헤르츠(Hertz) 단위의 주파수로 관측할 수 있고, 주파수가 높을수록 음이 높게 들립니다.
import matplotlib.pyplot as plt
import librosa.display
plt.figure(figsize =(16,6))
librosa.display.waveshow(y=data,sr=sample_rate)
plt.show()
2. 푸리에 변환
음성 데이터 분석을 위해 주파수 성분을 뽑을 때, 푸리에 변환을 사용합니다. 푸리에 변환은 입력 신호를 다양한 주파수를 가지는 주기 함수들로 분해하는 기법입니다. 주기 함수들을 분해함으로써 음성 데이터에서 노이즈 및 배경 소리로 부터 실제로 유용한 소리의 데이터, 즉 특징을 추출하기 위해 적용 됩니다. 먼저 푸리에 변환을 통해 음성 데이터의 파워 스펙트럼을 시각화 해보겠습니다.
fft = np.fft.fft(data)
# 복소공간 값 절댓갑 취해서, magnitude 구하기
magnitude = np.abs(fft)
# Frequency 값 만들기
f = np.linspace(0,sample_rate,len(magnitude))
# 푸리에 변환을 통과한 specturm은 대칭구조로 나와서 high frequency 부분 절반을 날려고 앞쪽 절반만 사용한다.
left_spectrum = magnitude[:int(len(magnitude)/2)]
left_f = f[:int(len(magnitude)/2)]
plt.figure(figsize=(16,6))
plt.plot(left_f, left_spectrum)
plt.xlabel("Frequency")
plt.ylabel("Magnitude")
plt.title("Power spectrum")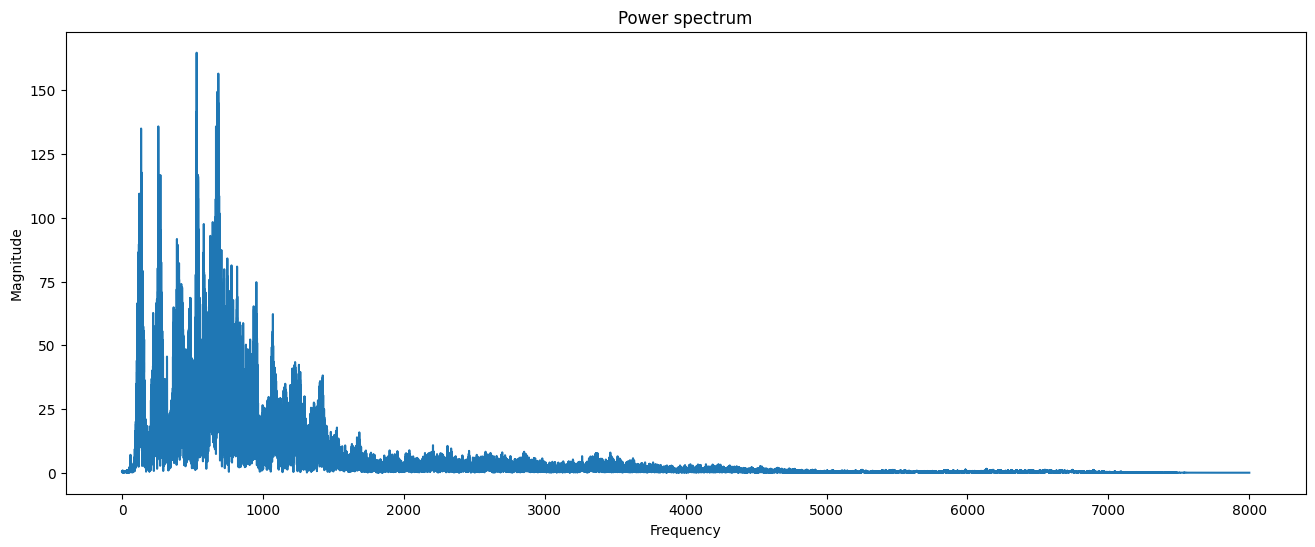
3. 스펙토그램(Spectogram)
푸리에 변환을 통해 특정 길이의 음성 조각이 각각의 주파수 성분을 얼마만큼 갖고 있는지를 의미하는 스펙트럼을 얻을 수 있습니다, 즉 음성에 들어있는 정보들을 수학적인 신호 처리를 거쳐 추출할 수 있습니다. 이후 여러 개의 스펙트럼을 시간 축에 나열하면 시간 변화에 따른 스펙트럼의 변화인 스펙트로그램이 시각화 됩니다.
# STFT -> spectrogram
hop_length = 512 # 전체 frame 수
n_fft = 2048 # frame 하나당 sample 수
# calculate duration hop length and window in seconds
hop_length_duration = float(hop_length)/sample_rate
n_fft_duration = float(n_fft)/sample_rate
# STFT
stft = librosa.stft(data, n_fft=n_fft, hop_length=hop_length)
# 복소공간 값 절댓값 취하기
magnitude = np.abs(stft)
# magnitude > Decibels
log_spectrogram = librosa.amplitude_to_db(magnitude)
# display spectrogram
plt.figure(figsize=(16,7))
librosa.display.specshow(log_spectrogram, sr=sample_rate, hop_length=hop_length)
plt.xlabel("Time")
plt.ylabel("Frequency")
plt.colorbar(format="%+2.0f dB")
plt.title("Spectrogram (dB)")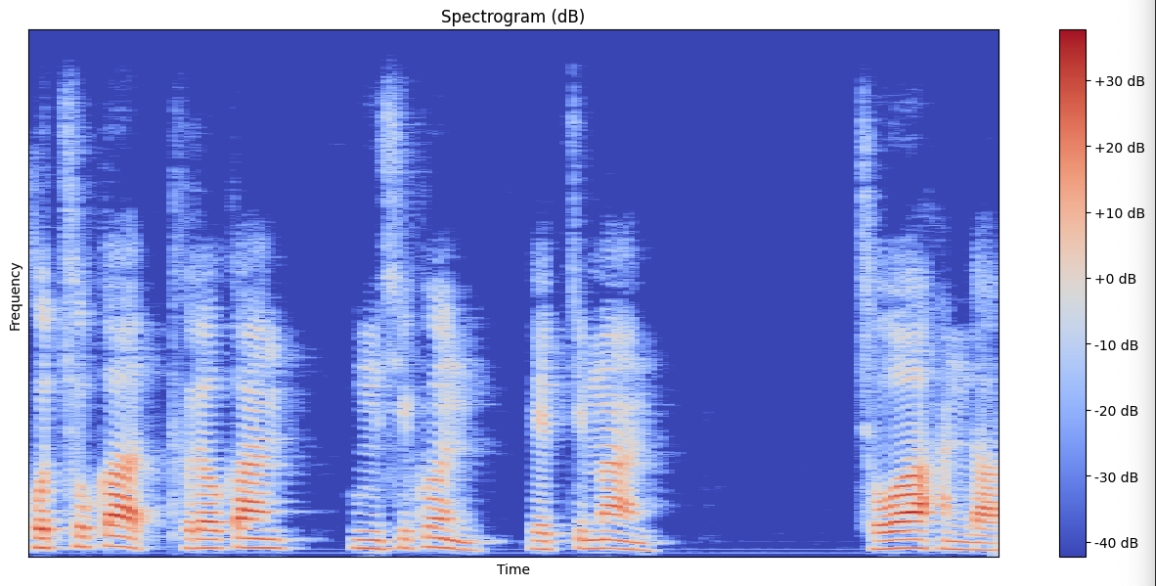
4. MFCC (Mel-frequency cepstral coefficients)
음성 데이터의 경우 같은 말이라도 데이터의 길이가 다를 수 있습니다. 예를 들어, 같은 "밥 먹었습니다."라는 음성을 담고 있어도 어떤 데이터는 2초, 어떤 데이터는 5초가 될 수 있습니다. 따라서 MFCC 알고리즘을 통해 음성 데이터를 특징 벡터화 해줍니다. MFCC는 입력된 소리 전체를 대상으로 하는 것이 아니라, 사람이 인지하기 좋은 Mel-scale로 음성 데이터를 모두 20 ~ 40ms로 나누어 구간에 대한 스펙트럼을 분석하여 푸리에 변환을 합니다. MFCC의 주요 인자는 다음과 같습니다.
- y: 오디오 데이터
- sr: sampling rate
- n_mfcc: retrun된 mfcc 개수. 증가할 수록 더 다양한 데이터 특징 추출함.
extracted_features = librosa.feature.mfcc(y=data, sr=16000, n_mfcc=20)
print(extracted_features.shape) # (n_mfcc, time_step)
# display MFCCs
plt.figure(figsize=(16,7))
librosa.display.specshow(extracted_features, sr=sample_rate, hop_length=hop_length)
plt.xlabel("Time")
plt.ylabel("MFCC coefficients")
plt.colorbar()
plt.title("MFCCs")
# show plots
plt.show()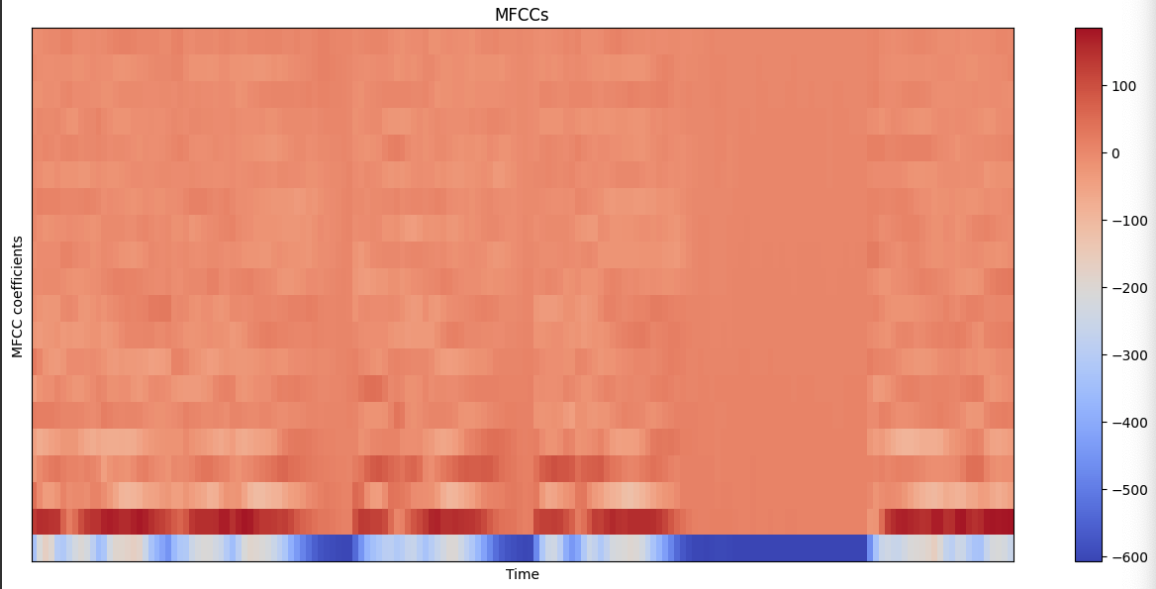
여기까지, 실제 데이터를 활용하여 음성 데이터를 시각화 해보았습니다. 보통 딥러닝에서는 MFCC 기법을 통해 음성 데이터를 이미지화 하고, 음성 데이터의 유용한 특징을 추출합니다. 다음 포스팅에서는 실제 원본 음성 데이터를 전처리하고, 모델에 활용하는 방법을 알아보겠습니다.
'Data Analytics' 카테고리의 다른 글
| [음성 인식 프로젝트] Whisper 파인튜닝 하기 (4) | 2024.03.14 |
|---|---|
| [음성 인식 모델 프로젝트] 음성 데이터 침묵구간 - 비침묵구간 분리하기 (2) | 2024.01.28 |
| 빅데이터분석기사 시험 난이도 (빅분기 7회 합격 후기) (10) | 2023.12.16 |