


GROUP BY 알아보기
GROUP BY는 특정 열을 기준으로 데이터를 그룹화하는 역할을 합니다. 예를 들어, 같은 부서에 속하는 직원들의 데이터를 묶어주어 평균 연봉을 계산하거나, 부서 별 직원들의 숫자를 구합니다. GROUP BY의 기본 예제는 아래와 같습니다.
SELECT customer_id, SUM(order_amount)
FROM orders
GROUP BY customer_id;위 커리는 전체 주문 데이터가 모여있는 'orders' 테이블에서 고객 id 별로 그룹화하고, 총 구매 량을 구합니다.
HAVING절과 함께 사용하기
HAVING 절은 GROUP BY와 함께 사용되며, 그룹화된 결과에 조건을 적용합니다. 이는 WHERE 절이, GROUP BY를 적용하기 전에 데이터를 필터링 하는 것과 차이가 있습니다. 예를 들어, 특정 주문 총액이 1000 달러 이상인 고객만을 조회하는 경우, HAVING 절을 사용합니다.
SELECT customer_id, SUM(order_amount)
FROM orders
GROUP BY customer_id
HAVING SUM(order_amount) >= 1000;
GROUP BY 특징
GROUP BY가 포함된 쿼리에서 중요한 점이 있습니다.
- groupby절에 쓰이지 않은 컬럼은 select 절에 올 수 없습니다.
- 단, aggfunc()을 사용해서 집계를 하면 올 수 가 있습니다. (e.g., SUM(order_amount))
- 만약, 집계할 수 없는 유니크한 값을 select에 불러올 때는, max(컬럼)을 사용합니다.
- 마지막으로, groupby를 적용하면 원래의 PK를 없애고, groupby를 적용하는 컬럼으로 PK 역할을 합니다.
GROUP BY 집계 함수
- COUNT()
- SUM()
- MAX()
- AVG()
- ... 등등
GROUP BY - ROLLUP
GROUP BY ROLLUP은 여러 열을 기준으로 데이터를 그룹화할 때 그룹의 계층을 생성합니다. 이때, 계층적이라는 표현이 중요합니다. 이를 통해 계층 별 토탈 및 전체 총계를 계산하는 데에 용이하며, 다양한 요약 레벨에서 데이터를 살펴볼 수 있습니다. 간단한 예제를 통해서 살펴보겠습니다.
CREATE TABLE orders (
order_date DATE,
product_id INT,
quantity INT
);
INSERT INTO orders VALUES
('2023-01-01', 1, 10),
('2023-01-01', 2, 5),
('2023-01-02', 1, 8),
('2023-01-02', 2, 12),
('2023-01-03', 1, 15),
('2023-01-03', 2, 7);먼저 (1)주문 날짜, (2)상품 id, (3)주문 수량으로 구성된 간단한 테이블을 생성합니다.
아이템 id는 1, 2 두 가지 아이템만 존재하도록 데이터를 추가했습니다.
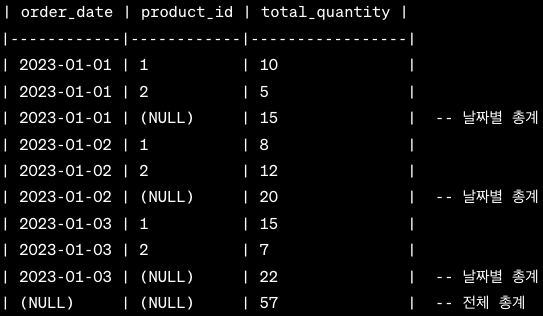
SELECT order_date, product_id, SUM(quantity) AS total_quantity
FROM orders
GROUP BY ROLLUP (order_date, product_id);
날짜와 상품 별로 그룹화를 해서 ROLLUP을 적용한 결과는 아래와 같습니다.
반응형
'SQL' 카테고리의 다른 글
| SQL 시간 데이터 다루기 (1) | 2024.01.14 |
|---|---|
| SQL 데이터 형식 알아보기(숫자형, 문자형, 날짜형) (0) | 2023.12.15 |
| SQL 기본 문법 알아보기 (0) | 2023.12.14 |
| SQL 기초 알아보기 (0) | 2023.12.14 |