

Contents
1. 데이터 로딩
2. leave_one_out
3. Negative sampling
4. Dataset & Dataloader
5. 모델 구성
6.Hit ratio & NDCG
7. 모델 적용
이번 포스팅에서는 NCF (neural collaborative filtering) 코드를 직접 구현하고, 실제 Yelp 데이터 세트에 적용해 보겠습니다. 대부분 코드가 movielens 데이터로만 구현되어 있어서, 작성해 보았습니다. 구글 colab 환경에서 진행해서 직관적이고 이해하기 쉬울 것이라고 기대합니다.
보통 NCF 코드 포스팅들을 찾아보면, 기존의 github 레포지토리를 실행하는 코드가 많은데, 본 포스팅에서는 손쉽게 colab 환경에서도 적용할 수 있도록 작성했습니다. PyTorch를 통해 구현하였고, yelp 데이터에 적용해보니 원논문에서 사용한 movielens나 pinterest 데이터에 비해 좋지 않은 hit ratio와 ndcg를 보여주었습니다. 또한 GMF 부분은 생략하고 MLP만 쌓은 NCF 모델링을 구성했습니다. NCF에 대한 설명은 아래 포스팅을 참조하기를 추천드립니다.
🐊[논문 리뷰] Neural Collaborative Filtering (2017) - https://ysg2997.tistory.com/5
데이터 로딩
데이터는 글로벌 레스토랑 사이트인 Yelp에서 제공하는 오픈데이터를 사용합니다(https://www.yelp.com/dataset). 결과부터 설명드리면, 전통적인 e-commerce 데이터 세트에 비해, 떨어지는 결과를 보입니다. 그래도 실제 데이터 세트에 적용해보고, 노트북 파일 형태로 구현해 보는 것에 초점을 두겠습니다.
먼저 구글 드라이브에서 저장된 데이터를 불러오기 위해 드라이브를 마운트 하고, 라이브러리를 임포트 해옵니다.
!pip install tensorboardX
from google.colab import drive
drive.mount('/content/drive')
import time
import random
import numpy as np
import pandas as pd
from tqdm import tqdm
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from tensorboardX import SummaryWriter
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
Yelp 데이터가 690만개의 데이터를 제공하다 보니, 간소화하기 위해 Philadephia 도시에서, 리뷰를 5개 이상 작성한 유저들의 방문 정보만 전처리 했습니다. 원본 데이터를 넣어도 되고, 목적에 맞도록 커스텀 된 데이터를 불러오면 됩니다. 먼저 전처리 된 데이터를 df로 불러옵니다.
df = pd.read_csv('custom.csv')
df.head()

총 596,499개의 유저 - 레스토랑 - 평점 - 리뷰 - 년도 데이터입니다.
모델의 입력으로 사용하기 위해, 문자열로 된 유저 ID와 레스토랑 ID를 각각 고유한 정수로 인코딩합니다.
37,465명의 유저와 14,342개의 레스토랑으로 이루어져있는 것을 확인할 수 있습니다.
from sklearn.preprocessing import LabelEncoder
# 유저와 레스토랑을 고유한 정수로 인코딩
le = LabelEncoder()
df['user_id'] = le.fit_transform(df['user_id'])
df['business_id'] = le.fit_transform(df['business_id'])
# 필요없는 열 제거
df.drop(['index', 'text', 'year'], axis=1, inplace=True)
df.head()
# 총 유저, 레스토랑 수
num_user = df['user_id'].nunique()
num_res = df['business_id'].nunique()
print('전체 유저 수:{0} / 아이템 수: {1}'.format(num_user, num_res))### result ###
전체 유저 수:37465 / 아이템 수: 14342
2. leave_one_out
다음은 데이터 세트를 train-test로 분리합니다. 보통 ML 작업에서는 데이터를 랜덤하게 분리합니다. 그러나 이렇게 되면, train에서는 학습한 유저가 test 세트에서는 존재하지 않을 수도 있습니다. NCF 논문에서는 leave_one_out 방식으로 데이터를 분리합니다.
참고로 본 실험에서는 유저의 레이팅 정보는 필요 없기 때문에, 구매 여부를 나타내는 [0, 1]로 바꾸었습니다.
df['stars'] = 1
# 본 데이터에는 timestamp가 없기 때문에, user_index로 만들어준다.
df['timestamp'] = df['user_id'].index
# 유저별로 groupby 한 후에, 가장 첫번째 데이터를 test 세트로 분리한다.
df['rank_latest'] = df.groupby(['user_id'])['timestamp'].rank(method='first', ascending=False)
train_ratings = df[df['rank_latest'] != 1]
test_ratings = df[df['rank_latest'] == 1]
train_ratings = train_ratings[['user_id', 'business_id', 'stars']]
test_ratings = test_ratings[['user_id', 'business_id', 'stars']]
print('훈련 데이터셋 유저 수:', train_ratings['user_id'].nunique())
print('테스트 데이터셋 유저 수:', test_ratings['user_id'].nunique())
훈련 세트와 테스트 세트에 동일한 유저 수가 있는 것을 확인할 수 있습니다.
각 유저별로 하나 씩의 구매정보만 가져왔기 때문에, 테스트 세트의 크기 자체도 37,465개가 됩니다.
### result ###
훈련 데이터셋 유저 수: 37465
테스트 데이터셋 유저 수: 37465
3. Negative sampling
Negative sampling 역시 NCF 논문에 핵심입니다. 본 실험에서는 구매여부(0 or 1)를 예측하지만, 데이터 세트에는 구매한 1 데이터 밖에 존재하지 않습니다. 따라서 구매하지 않은 데이터 (0)을 만들어주기 위해, 전체 아이템 (레스토랑) 풀에서 랜덤 하게 만들어 줍니다.
# 전체 레스토랑 풀
all_rest = df['business_id'].unique()
# 빈 리스트 생성
users, items, labels= [], [], []
# 훈련 세트에 존재하는 유저-레스토랑 페어
user_item_set = set(zip(train_ratings['user_id'], train_ratings['business_id']))
# 4:1 비율로, 구매하지 않은 0 라벨을 만들어준다.
num_negatives = 4
for (u, i) in tqdm(user_item_set):
users.append(u)
items.append(i)
labels.append(1) # items that the user has interacted with are positive
for _ in range(num_negatives):
# randomly select an item
negative_item = np.random.choice(all_rest)
# check that the user has not interacted with this item
while (u, negative_item) in user_item_set:
negative_item = np.random.choice(all_rest)
users.append(u)
items.append(negative_item)
labels.append(0)
users = np.array(users)
items = np.array(items)
labels = np.array(labels)
train_df = pd.DataFrame({'user_id':users, 'business_id':items, 'labels':labels})
train_df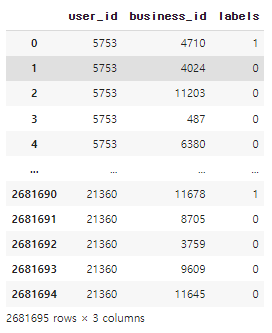
구매하지 않은 (방문하지 않은) 레이블 0이 각각 4개씩 만들어졌습니다.
테스트 데이터는 negative sampling을 적용하지 않고, 나중에 Dataloader에서 배치를 적용해줄 예정입니다.
test_df = test_ratings.rename({'stars':'labels'}, axis=1)
test_df = test_df.reset_index().drop('index', axis=1)
4. Dataset & Dataloader
파이토치 모델에 적용하기 위해, 커스텀 Dataset을 만들고, Dataloader를 적용해주었습니다.
원 논문과 마찬가지로 batch_size를 지정했고, 주목할 점은 test_dataloader의 배치 사이즈입니다. 이 부분은 원논문의 Evaluation Protocols 섹션에 잘 나와있습니다. 각 test_dataloader 배치에 대해 Hit-ratio와 NDCG를 체크할 예정입니다.
class Rating_Datset(torch.utils.data.Dataset):
def __init__(self, dataset):
self.user = dataset['user_id']
self.item = dataset['business_id']
self.label = dataset['labels']
def __len__(self):
return len(self.user)
def __getitem__(self, idx):
u = self.user[idx]
i = self.item[idx]
l = self.label[idx]
return torch.tensor(u), torch.tensor(i), torch.tensor(l)
train_dataset = Rating_Datset(train_df)
test_dataset = Rating_Datset(test_df1)
train_dataloader = DataLoader(train_dataset, batch_size=256)
test_dataloader = DataLoader(test_dataset, batch_size=99)
5. 모델 구성
앞서 언급한 대로 MLP를 적용한 NCF만 구현한 모델입니다.
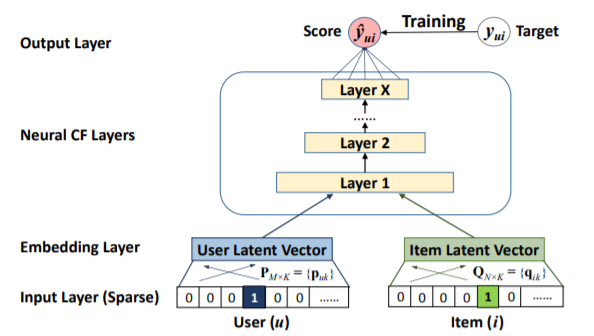
간단히 유저의 수와 레스토랑 수로 이루어진 임베딩을 구현했습니다. 이때 임베딩 차원을 8로 지정합니다.
이후 [32->16->8] 크기의 레이어 3개를 통과하고, 구매 여부[0,1]를 예측하기 때문에 마지막 활성화 함수는 sigmoid를 적용했습니다.
model 인스턴스를 생성하고, GPU device로 전달합니다.
class NCF(nn.Module):
def __init__(self, num_users, num_items):
super(NCF, self).__init__()
self.num_users = num_users
self.num_items = num_items
self.embed_dim = 16
self.relu=nn.ReLU()
self.sigmoid= nn.Sigmoid()
self.embedding_user = nn.Embedding(num_embeddings=self.num_users, embedding_dim=self.embed_dim)
self.embedding_item = nn.Embedding(num_embeddings=self.num_items, embedding_dim=self.embed_dim)
self.fc1 = nn.Linear(in_features=32, out_features=16)
self.fc2 = nn.Linear(in_features=16, out_features=8)
self.fc3 = nn.Linear(in_features=8, out_features=1)
def forward(self, user_indices, item_indices):
user_embedding = self.embedding_user(user_indices)
item_embedding = self.embedding_item(item_indices)
vector = torch.cat([user_embedding, item_embedding], dim=-1) # the concat latent vector
x = self.fc1(vector)
x = self.relu(x)
# x = nn.BatchNorm1d()(x)
# x = nn.Dropout(p=0.1)(x)
x = self.fc2(x)
x = self.relu(x)
x = self.fc3(x)
out = self.sigmoid(x)
return out.squeeze()
num_users = df['user_id'].nunique()+1
num_items = df['business_id'].nunique()+1
model = NCF(num_users, num_items)
model.to(device)### result ###
NCF(
(relu): ReLU()
(sigmoid): Sigmoid()
(embedding_user): Embedding(37466, 16)
(embedding_item): Embedding(14343, 16)
(fc1): Linear(in_features=32, out_features=16, bias=True)
(fc2): Linear(in_features=16, out_features=8, bias=True)
(fc3): Linear(in_features=8, out_features=1, bias=True)
)
6. Hit ratio & NDCG
- Hit ratio: 추천된 상위 K개의 아이템 중 실제로 사용자가 선호하는 아이템이 얼마나 포함되었는지를 측정합니다.
- NDCG (Normalized Discounted Cumulative Gain): 추천된 상위 K개의 아이템에 대해, 사용자의 관심도에 따라 순위를 매기고 할인된 누적 이득을 정규화한 값으로, 더 높은 NDCG 값은 더 좋은 추천을 의미합니다.
두 평가 지표에 대한 이야기는 나중에 포스팅으로 자세히 다룰 예정입니다.
def hit(gt_item, pred_items):
if gt_item in pred_items:
return 1
return 0
def ndcg(gt_item, pred_items):
if gt_item in pred_items:
index = pred_items.index(gt_item)
return np.reciprocal(np.log2(index + 2))
return 0
def metrics(model, test_loader, top_k):
HR, NDCG = [], []
for user, item, _ in test_loader:
user = user.to(device)
item = item.to(device)
predictions = model(user, item)
# 가장 높은 top_k개 선택
_, indices = torch.topk(predictions, top_k)
# 해당 상품 index 선택
recommends = torch.take(item, indices).cpu().numpy().tolist()
# 정답값 선택
gt_item = item[0].item()
HR.append(hit(gt_item, recommends))
NDCG.append(ndcg(gt_item, recommends))
return np.mean(HR), np.mean(NDCG)
7. 모델 적용
먼저 기본적으로 learning rate와 손실함수, 옵티마이저를 정의합니다.
손실 함수는 binary crossentropy 함수입니다.
top_k는 hit ratio와 ndcg를 계산할 때, 얼마나 많은 아이템을 예측할지를 나타냅니다. 당연히 tok_k가 클수록 많은 예측을 하기 때문에 성능이 좋게 나옵니다. top_k는 10으로 지정합니다.
기본적인 훈련 과정은 pytorch 모델들과 크게 다르지 않습니다. tensorboardX에 시각화를 하려고 SummaryWriter를 불러왔는데, 크게 훈련이 되지 않아 결과는 생략했습니다.
총 10번의 epoch 동안 학습을 진행했습니다.
각 에포크마다 model의 평가를 실시하는데, 위의 metrics 함수를 보면, 각 test_loader의 배치 사이즈마다 hit ratio와 ndcg를 계산하고, 배치들의 최종 평균값을 반환합니다.
learning_rate = 0.001
loss_fn = nn.BCELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
from tqdm import tqdm
size = len(train_dataloader.dataset)
count, best_hr = 0, 0
top_k= 10
writer = SummaryWriter() # for visualization
for epoch in range(10):
print('##### EPOCH {} #####'.format(epoch + 1))
model.train() # Enable dropout (if have).
start_time = time.time()
for batch, (user, item, label) in enumerate(tqdm(train_dataloader)):
user = user.to(device)
item = item.to(device)
label = label.to(device)
# gradient 초기화
model.zero_grad()
prediction = model(user, item)
loss = loss_fn(prediction.to(torch.float32), label.to(torch.float32))
loss.backward()
optimizer.step()
writer.add_scalar("data/loss", loss.item(), count)
count += 1
model.eval()
HR, NDCG = metrics(model, test_dataloader, top_k)
elapsed_time = time.time() - start_time
print(
"The time elapse of epoch {:03d}".format(epoch)
+ " is: "
+ time.strftime("%H: %M: %S", time.gmtime(elapsed_time))
)
print("HR: {:.3f}\tNDCG: {:.3f}".format(np.mean(HR), np.mean(NDCG)))
if HR > best_hr:
best_hr, best_ndcg, best_epoch = HR, NDCG, epoch
writer.flush()
print(
"End. Best epoch {:03d}: HR = {:.3f}, NDCG = {:.3f}".format(
best_epoch, best_hr, best_ndcg
)
)### result ###
##### EPOCH 1 #####
100%|██████████| 10476/10476 [02:05<00:00, 83.37it/s]
The time elapse of epoch 000 is: 00: 02: 06
HR: 0.129 NDCG: 0.086
##### EPOCH 2 #####
100%|██████████| 10476/10476 [02:06<00:00, 83.04it/s]
The time elapse of epoch 001 is: 00: 02: 07
HR: 0.132 NDCG: 0.087
##### EPOCH 3 #####
100%|██████████| 10476/10476 [02:03<00:00, 84.92it/s]
The time elapse of epoch 002 is: 00: 02: 04
HR: 0.142 NDCG: 0.090
##### EPOCH 4 #####
100%|██████████| 10476/10476 [02:04<00:00, 83.96it/s]
The time elapse of epoch 003 is: 00: 02: 05
HR: 0.148 NDCG: 0.091
##### EPOCH 5 #####
100%|██████████| 10476/10476 [02:05<00:00, 83.55it/s]
The time elapse of epoch 004 is: 00: 02: 06
HR: 0.153 NDCG: 0.093
##### EPOCH 6 #####
100%|██████████| 10476/10476 [02:05<00:00, 83.64it/s]
The time elapse of epoch 005 is: 00: 02: 06
HR: 0.150 NDCG: 0.093
##### EPOCH 7 #####
100%|██████████| 10476/10476 [02:06<00:00, 82.75it/s]
The time elapse of epoch 006 is: 00: 02: 07
HR: 0.158 NDCG: 0.096
##### EPOCH 8 #####
100%|██████████| 10476/10476 [02:03<00:00, 84.78it/s]
The time elapse of epoch 007 is: 00: 02: 04
HR: 0.161 NDCG: 0.097
##### EPOCH 9 #####
100%|██████████| 10476/10476 [02:02<00:00, 85.84it/s]
The time elapse of epoch 008 is: 00: 02: 03
HR: 0.156 NDCG: 0.093
##### EPOCH 10 #####
100%|██████████| 10476/10476 [02:04<00:00, 84.11it/s]
The time elapse of epoch 009 is: 00: 02: 05
HR: 0.164 NDCG: 0.097
End. Best epoch 009: HR = 0.164, NDCG = 0.097결과가 크게 좋은 것 같지는 않습니다. top_k를 30으로 늘려보면 3배 정도 향상된 결과를 보여줍니다.
### result when top_k=30 ###
##### EPOCH 0 #####
100%|██████████| 10476/10476 [02:08<00:00, 81.65it/s]
The time elapse of epoch 000 is: 00: 02: 09
HR: 0.361 NDCG: 0.144
##### EPOCH 1 #####
100%|██████████| 10476/10476 [02:06<00:00, 82.97it/s]
The time elapse of epoch 001 is: 00: 02: 07
HR: 0.364 NDCG: 0.144
##### EPOCH 2 #####
100%|██████████| 10476/10476 [02:08<00:00, 81.75it/s]
The time elapse of epoch 002 is: 00: 02: 09
HR: 0.364 NDCG: 0.145
##### EPOCH 3 #####
100%|██████████| 10476/10476 [02:09<00:00, 81.06it/s]
The time elapse of epoch 003 is: 00: 02: 10
HR: 0.364 NDCG: 0.146
##### EPOCH 4 #####
100%|██████████| 10476/10476 [02:10<00:00, 80.46it/s]
The time elapse of epoch 004 is: 00: 02: 11
HR: 0.364 NDCG: 0.147
##### EPOCH 5 #####
100%|██████████| 10476/10476 [02:08<00:00, 81.76it/s]
The time elapse of epoch 005 is: 00: 02: 09
HR: 0.369 NDCG: 0.146
##### EPOCH 6 #####
100%|██████████| 10476/10476 [02:08<00:00, 81.70it/s]
The time elapse of epoch 006 is: 00: 02: 09
HR: 0.372 NDCG: 0.146
##### EPOCH 7 #####
100%|██████████| 10476/10476 [02:07<00:00, 82.27it/s]
The time elapse of epoch 007 is: 00: 02: 08
HR: 0.383 NDCG: 0.146
##### EPOCH 8 #####
100%|██████████| 10476/10476 [02:09<00:00, 80.84it/s]
The time elapse of epoch 008 is: 00: 02: 10
HR: 0.388 NDCG: 0.147
##### EPOCH 9 #####
100%|██████████| 10476/10476 [02:07<00:00, 82.36it/s]
The time elapse of epoch 009 is: 00: 02: 08
HR: 0.388 NDCG: 0.145
End. Best epoch 008: HR = 0.388, NDCG = 0.147
이상으로 PyTorch로 NCF 모델을 코드로 구현해 보았습니다. NCF 모델을 검색해 보면 기존에 코드에 대한 리뷰가 많은데, 부족하더라도 본 포스팅을 통해 이해에 도움이 되고, 실제 데이터에도 적용하는 것에 도움이 되었으면 합니다.
'Recommender System' 카테고리의 다른 글
| NDCF, MAP - 실제 추천 모델을 통해 평가 지표 이해하기(코드 구현) (0) | 2023.07.10 |
|---|---|
| 그래프 기반 추천시스템의 이해 (1) | 2023.06.21 |
| [코드 리뷰] PyTorch로 NCF 모델 구현하기 (without pre-training) (0) | 2022.11.28 |