

이전에 포스팅 했던 Transformer 이론을 PyTorch 코드로 이해하기 위한 포스팅이다.
🐊 Transfomer 이론 : https://ysg2997.tistory.com/8
[DL] Transformer: Attention Is All You Need (2017)
🐊 논문 링크: https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. Advances in
ysg2997.tistory.com
파이토치에는 nn.Transformer로 트랜스포머가 구현되어 있다.
<공식문서>
https://pytorch.org/docs/stable/generated/torch.nn.Transformer.html#transformer
torch.nn.Transformer
(d_model=512, nhead=8, num_encoder_layers=6, num_decoder_layers=6, dim_feedforward=2048, dropout=0.1, activation=, custom_encoder=None, custom_decoder=None, layer_norm_eps=1e-05, batch_first=False, norm_first=False, device=None, dtype=None)
파라미터 default 값은 위와 같다. 아래는 간단한 모델 예시 코드이다.
인풋은 src, 아웃풋은 tgt 변수로 정의한다.
# Example
transformer_model = nn.Transformer(nhead=16, num_encoder_layers=12)
src = torch.rand((10, 32, 512))
tgt = torch.rand((20, 32, 512))
out = transformer_model(src, tgt)기본 Transformer 구조
먼저 간단히 nn.Module 모델을 만드는 것을 살펴보겠다.
import torch
import torch.nn as nn
import torch.optim as optim
import math
import numpy as np
import randomclass Transformer(nn.Module):
def __init__(self, num_tokens, dim_model, num_heads, num_encoder_layers, num_decoder_layers, dropout_p, ):
super().__init__()
# Layers
self.transformer = nn.Transformer(
d_model=dim_model,
nhead=num_heads,
num_encoder_layers=num_encoder_layers,
num_decoder_layers=num_decoder_layers,
dropout=dropout_p,
)
def forward(self):
passnn.Transformer의 주요 파라미터는 다음과 같다.
- d_model: 트랜스포머의 인코더와 디코더에서의 정해진 입력과 출력의 크기를 의미 (default=512)
- num_encoder_layers: 인코더가 총 몇 층으로 구성되었는지를 의미. (default=6)
- num_decoder_layers: 디코더가 총 몇 층으로 구성되었는지를 의미. (default=6)
- nhead: 멀티헤드 어텐션 모델의 헤드 수 (default=8)
- dim_feedforward: FFNN 은닉층의 크기(default=2048)
Positional encoding
Positional encoding, Embedding, Linear는 따로 만들어 줘야 한다.
Positional Encoding 함수는 아래와 같고, 코드는 간단히 식 구현 및 dropout, 잔차 연결을 구현한다.
$$ PE(pos,2i+1)=\cos(10000_{2i}/d_{model}pos) $$
$$ PE(pos,2i+1)=\cos(10000_{2i}/d_{model}pos) $$
class PositionalEncoding(nn.Module):
def __init__(self, dim_model, dropout_p, max_len):
super().__init__()
self.dropout = nn.Dropout(dropout_p)
# Encoding - From formula
pos_encoding = torch.zeros(max_len, dim_model)
positions_list = torch.arange(0, max_len, dtype=torch.float).view(-1, 1) # 0, 1, 2, 3, 4, 5
division_term = torch.exp(torch.arange(0, dim_model, 2).float() * (-math.log(10000.0)) / dim_model) # 1000^(2i/dim_model)
pos_encoding[:, 0::2] = torch.sin(positions_list * division_term)
pos_encoding[:, 1::2] = torch.cos(positions_list * division_term)
# Saving buffer (same as parameter without gradients needed)
pos_encoding = pos_encoding.unsqueeze(0).transpose(0, 1)
self.register_buffer("pos_encoding", pos_encoding)
def forward(self, token_embedding: torch.tensor) -> torch.tensor:
# Residual connection + pos encoding
return self.dropout(token_embedding + self.pos_encoding[:token_embedding.size(0), :])register_buffer로 layer를 등록하면 optimizer가 업데이트 하지 않는다.
Transformer 모델 구체화
기본 모델을 구체화 한 코드이다. Maseked Multi-head Attention 및 Embedding, Positional Encoding이 구현되었다.


Decoder에서 뒤 토큰에 대한 마스킹을 처리하고, 위 그림과 같이 삼각 행렬로 나타낸다.
아래는 마스킹 된 패딩 토큰이 있는 위치를 True로 표현한 것이다.
class Transformer(nn.Module):
# Constructor
def __init__(self, num_tokens, dim_model, num_heads, num_encoder_layers, num_decoder_layers, dropout_p,):
super().__init__()
# INFO
self.model_type = "Transformer"
self.dim_model = dim_model
# LAYERS
self.positional_encoder = PositionalEncoding(dim_model=dim_model, dropout_p=dropout_p, max_len=5000)
self.embedding = nn.Embedding(num_tokens, dim_model)
self.transformer = nn.Transformer(
d_model=dim_model,
nhead=num_heads,
num_encoder_layers=num_encoder_layers,
num_decoder_layers=num_decoder_layers,
dropout=dropout_p,
)
self.out = nn.Linear(dim_model, num_tokens)
def forward(self, src, tgt, tgt_mask=None, src_pad_mask=None, tgt_pad_mask=None):
# src, Tgt size -> (batch_size, src sequence length)
# Embedding + positional encoding - Out size = (batch_size, sequence length, dim_model)
src = self.embedding(src) * math.sqrt(self.dim_model)
tgt = self.embedding(tgt) * math.sqrt(self.dim_model)
src = self.positional_encoder(src)
tgt = self.positional_encoder(tgt)
src = src.permute(1,0,2)
tgt = tgt.permute(1,0,2)
# Transformer blocks - Out size = (sequence length, batch_size, num_tokens)
transformer_out = self.transformer(src, tgt, tgt_mask=tgt_mask, src_key_padding_mask=src_pad_mask, tgt_key_padding_mask=tgt_pad_mask)
out = self.out(transformer_out)
return out
def get_tgt_mask(self, size) -> torch.tensor:
mask = torch.tril(torch.ones(size, size) == 1) # Lower triangular matrix
mask = mask.float()
mask = mask.masked_fill(mask == 0, float('-inf')) # Convert zeros to -inf
mask = mask.masked_fill(mask == 1, float(0.0)) # Convert ones to 0
return mask
def create_pad_mask(self, matrix: torch.tensor, pad_token: int) -> torch.tensor:
return (matrix == pad_token)- # Layer에서 num_tokens 길이를 가진 입력 시퀀스가 dim_model 차원으로 임베딩 된다.
- forward()에서 처리되는 차원에 유의해야 한다.
- Transformer Encoder는 입력으로 [seq_len, batch_len, embedding_dim]을 기대한다.
- 이를 batch_fisrt를 적용하기 위해 premute(1,0,2)를 해서 [batch_len, seq_len, embedding_dim]로 만든다. - get_tgt_mask() 함수는 디코더에 적용되는 Mask를 만들어주고, 삼각행렬 형태이다.
- # Transformer blocks에서 transfomer의 파라미터로 src_mask, key_padding_mask가 나온다.
공식문서에 따르면, src_mask는 단지 attention weights를 마스킹 하기 위한 스퀘어 행렬이고
src_key_padding_mask는 src 시퀀스에서 특정한 토큰을 마스킹하기 위한 padding maker에 가깝다고 한다.
학습 데이터 생성
학습을 목적으로 fake data를 만든다. 코드가 조금 복잡한데, 단순히 데이터를 만드는 코드이므로 크게 중요하지는 않다.
결과는 다음과 같다. 왼쪽이 입력, 오른쪽이 출력 시퀀스이다.
- 1, 1, 1, 1, 1, 1, 1, 1 → 1, 1, 1, 1, 1, 1, 1, 1
- 0, 0, 0, 0, 0, 0, 0, 0 → 0, 0, 0, 0, 0, 0, 0, 0
- 1, 0, 1, 0, 1, 0, 1, 0 → 1, 0, 1, 0, 1, 0, 1, 0
- 0, 1, 0, 1, 0, 1, 0, 1 → 0, 1, 0, 1, 0, 1, 0, 1
def generate_random_data(n):
SOS_token = np.array([2])
EOS_token = np.array([3])
length = 8
data = []
# 1,1,1,1,1 -> 1,1,1,1,1
for i in range(n // 3):
X = np.concatenate((SOS_token, np.ones(length), EOS_token))
y = np.concatenate((SOS_token, np.ones(length), EOS_token))
data.append([X, y])
# 0,0,0,0 -> 0,0,0,0
for i in range(n // 3):
X = np.concatenate((SOS_token, np.zeros(length), EOS_token))
y = np.concatenate((SOS_token, np.zeros(length), EOS_token))
data.append([X, y])
# 1,0,1,0 -> 1,0,1,0,1
for i in range(n // 3):
X = np.zeros(length)
start = random.randint(0, 1)
X[start::2] = 1
y = np.zeros(length)
if X[-1] == 0:
y[::2] = 1
else:
y[1::2] = 1
X = np.concatenate((SOS_token, X, EOS_token))
y = np.concatenate((SOS_token, y, EOS_token))
data.append([X, y])
np.random.shuffle(data)
return data
#크기가 16인 배치 형태로 만들어 줍니다.
def batchify_data(data, batch_size=16, padding=False, padding_token=-1):
batches = []
for idx in range(0, len(data), batch_size):
# batch_size 크기가 아닌 경우 마지막 비트를 얻지 않도록 합니다.
if idx + batch_size < len(data):
# 여기서 배치의 최대 길이를 가져와 PAD 토큰으로 길이를 정규화해야 합니다.
if padding:
max_batch_length = 0
# batch에서 가장 긴 문장 가져오기
for seq in data[idx : idx + batch_size]:
if len(seq) > max_batch_length:
max_batch_length = len(seq)
# 최대 길이에 도달할 때까지 X 패딩 토큰을 추가합니다.
for seq_idx in range(batch_size):
remaining_length = max_bath_length - len(data[idx + seq_idx])
data[idx + seq_idx] += [padding_token] * remaining_length
batches.append(np.array(data[idx : idx + batch_size]).astype(np.int64))
print(f"{len(batches)} batches of size {batch_size}")
return batches
train_data = generate_random_data(9000)
val_data = generate_random_data(3000)
train_dataloader = batchify_data(train_data)
val_dataloader = batchify_data(val_data)562 batches of size 16
187 batches of size 16중간에 1, 1, 1, 1....을 만드는 부분만 가져와서 보았다.
data = []
X = np.concatenate((SOS_token, np.ones(length), EOS_token))
y = np.concatenate((SOS_token, np.ones(length), EOS_token))
data.append([X, y])
data
>>> [[array([2., 1., 1., 1., 1., 1., 1., 1., 1., 3.]),
array([2., 1., 1., 1., 1., 1., 1., 1., 1., 3.])]]훈련 및 검증
device = "cuda" if torch.cuda.is_available() else "cpu"
model = Transformer(num_tokens=4,
dim_model=8,
num_heads=2,
num_encoder_layers=3,
num_decoder_layers=3,
dropout_p=0.1).to(device)
opt = torch.optim.SGD(model.parameters(), lr=0.01)
loss_fn = nn.CrossEntropyLoss()
모델 훈련시 주의사항이다.
- target tensor는 예측 중에 모델에 전달된다.
- 다음 단어를 숨기기 위해 target mask가 생성된다.
- padding mask가 생성되어 모델에 전달된다.
- Transformer에 target 입력으로 들어가는 tensor는 오른쪽으로 1만큼 이동해야한다.
아래 코드 y_input과 y_expected로 구현한다.
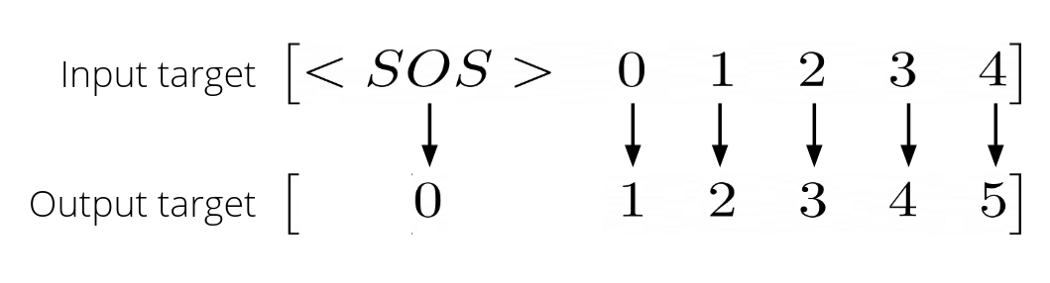
# Train
def train_loop(model, opt, loss_fn, dataloader):
model.train()
total_loss = 0
for batch in dataloader:
X, y = batch[:, 0], batch[:, 1]
X, y = torch.tensor(X).to(device), torch.tensor(y).to(device)
# 이제 tgt를 1만큼 이동하여 <SOS>를 사용하여 pos 1에서 토큰을 예측
y_input = y[:,:-1]
y_expected = y[:,1:]
# 다음 단어를 마스킹하려면 마스크 가져오기
sequence_length = y_input.size(1)
tgt_mask = model.get_tgt_mask(sequence_length).to(device)
# X, y_input 및 tgt_mask를 전달하여 표준 training
pred = model(X, y_input, tgt_mask)
# Permute 를 수행하여 batch first
pred = pred.permute(1, 2, 0)
loss = loss_fn(pred, y_expected)
opt.zero_grad()
loss.backward()
opt.step()
total_loss += loss.detach().item()
return total_loss / len(dataloader)
# Validation
optimizer가 필요하지 않고, with torch.no_grad()를 적용한다.
def validation_loop(model, loss_fn, dataloader):
model.eval()
total_loss = 0
with torch.no_grad():
for batch in dataloader:
X, y = batch[:, 0], batch[:, 1]
X, y = torch.tensor(X, dtype=torch.long, device=device), torch.tensor(y, dtype=torch.long, device=device)
y_input = y[:,:-1]
y_expected = y[:,1:]
sequence_length = y_input.size(1)
tgt_mask = model.get_tgt_mask(sequence_length).to(device)
pred = model(X, y_input, tgt_mask)
pred = pred.permute(1, 2, 0)
loss = loss_fn(pred, y_expected)
total_loss += loss.detach().item()
return total_loss / len(dataloader)훈련 및 검증 실행
def fit(model, opt, loss_fn, train_dataloader, val_dataloader, epochs):
# plotting하기 위한 리스트 생성
train_loss_list, validation_loss_list = [], []
print("Training and validating model")
for epoch in range(epochs):
print("-"*25, f"Epoch {epoch + 1}","-"*25)
train_loss = train_loop(model, opt, loss_fn, train_dataloader)
train_loss_list += [train_loss]
validation_loss = validation_loop(model, loss_fn, val_dataloader)
validation_loss_list += [validation_loss]
print(f"Training loss: {train_loss:.4f}")
print(f"Validation loss: {validation_loss:.4f}")
print()
return train_loss_list, validation_loss_list
train_loss_list, validation_loss_list = fit(model, opt, loss_fn, train_dataloader, val_dataloader, 10)10 에포크 동안 학습을 수행한다.
Traning and validating model
------------------------- Epoch 1 -------------------------
Training loss: 0.5674
Validation loss: 0.3895
------------------------- Epoch 2 -------------------------
Training loss: 0.3846
Validation loss: 0.3427
------------------------- Epoch 3 -------------------------
Training loss: 0.3422
Validation loss: 0.2756
------------------------- Epoch 4 -------------------------
Training loss: 0.3037
Validation loss: 0.2345
------------------------- Epoch 5 -------------------------
Training loss: 0.2722
Validation loss: 0.1991
------------------------- Epoch 6 -------------------------
Training loss: 0.2543
Validation loss: 0.2081
------------------------- Epoch 7 -------------------------
Training loss: 0.2409
Validation loss: 0.1593
------------------------- Epoch 8 -------------------------
Training loss: 0.2324
Validation loss: 0.1649
------------------------- Epoch 9 -------------------------
Training loss: 0.2244
Validation loss: 0.1517
------------------------- Epoch 10 -------------------------
Training loss: 0.2195
Validation loss: 0.1488
plt.plot(train_loss_list, label = "Train loss")
plt.plot(validation_loss_list, label = "Validation loss")
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Loss vs Epoch')
plt.legend()
plt.show()
에포크가 진행될 수록 Loss가 감소하는 것을 확인할 수 있다.
Inference
마지막으로 예측 함수를 만들어 테스트한다.
def predict(model, input_sequence, max_length=15, SOS_token=2, EOS_token=3):
model.eval()
y_input = torch.tensor([[SOS_token]], dtype=torch.long, device=device)
num_tokens = len(input_sequence[0])
for _ in range(max_length):
# Get source mask
tgt_mask = model.get_tgt_mask(y_input.size(1)).to(device)
pred = model(input_sequence, y_input, tgt_mask)
next_item = pred.topk(1)[1].view(-1)[-1].item() # num with highest probability
next_item = torch.tensor([[next_item]], device=device)
# Concatenate previous input with predicted best word
y_input = torch.cat((y_input, next_item), dim=1)
# Stop if model predicts end of sentence
if next_item.view(-1).item() == EOS_token:
break
return y_input.view(-1).tolist()
# Here we test some examples to observe how the model predicts
examples = [
torch.tensor([[2, 0, 0, 0, 0, 0, 0, 0, 0, 3]], dtype=torch.long, device=device),
torch.tensor([[2, 1, 1, 1, 1, 1, 1, 1, 1, 3]], dtype=torch.long, device=device),
torch.tensor([[2, 1, 0, 1, 0, 1, 0, 1, 0, 3]], dtype=torch.long, device=device),
torch.tensor([[2, 0, 1, 0, 1, 0, 1, 0, 1, 3]], dtype=torch.long, device=device),
torch.tensor([[2, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 3]], dtype=torch.long, device=device),
torch.tensor([[2, 0, 1, 3]], dtype=torch.long, device=device)
]
for idx, example in enumerate(examples):
result = predict(model, example)
print(f"Example {idx}")
print(f"Input: {example.view(-1).tolist()[1:-1]}")
print(f"Continuation: {result[1:-1]}")
print()Example 0
Input: [0, 0, 0, 0, 0, 0, 0, 0]
Continuation: [0, 0, 0, 0, 0, 0, 0, 0, 0]
Example 1
Input: [1, 1, 1, 1, 1, 1, 1, 1]
Continuation: [1, 1, 1, 1, 1, 1, 1, 1, 1]
Example 2
Input: [1, 0, 1, 0, 1, 0, 1, 0]
Continuation: [0, 1, 0, 1, 0, 1, 0, 1]
Example 3
Input: [0, 1, 0, 1, 0, 1, 0, 1]
Continuation: [0, 1, 0, 1, 0, 1, 0, 1]
Example 4
Input: [0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0]
Continuation: [0, 1, 0, 1, 0, 1, 0, 1, 0]
Example 5
Input: [0, 1]
Continuation: [0, 1, 0, 1, 0, 1, 0, 1]거의 완벽하게 예측한 결과를 확인할 수 있다.
본 포스팅은 Daniel Melchor의 블로그를 참고하여 작성했습니다.
https://towardsdatascience.com/a-detailed-guide-to-pytorchs-nn-transformer-module-c80afbc9ffb1
'DL > Pytorch' 카테고리의 다른 글
| [Pytorch] Pytorch 모델링 구조 (1) | 2023.01.09 |
|---|---|
| [PyTorch] Tensorboard 사용하기 (colab) (0) | 2022.11.26 |
| [PyTorch] Weight Initialization (기울기 초기화) (0) | 2022.11.25 |
| [PyTorch] Tensor 차원, 크기 다루기 (0) | 2022.11.21 |
| [PyTorch] Early Stopping & LRScheduler (0) | 2022.11.18 |